Stable Diffusion Models Study Guide

We have all heard models related to Stable Diffusion, but what are they? The following articles will help you completely master the classification and use of Stable Diffusion models.
Table of Contents
The concept of the model
Let’s first look at what exactly a model in Stable Diffusion is. The definition of the model in Wikipedia is very simple: using a simpler thing to represent another thing. In other words, a model represents an abstract expression of something.
In AIGC, to make machines show intelligence, researchers use machine learning methods to allow computers to learn from data and perform various tasks in the direction expected by humans. For AI painting, we train the algorithm program to let the machine learn the information characteristics of various pictures. We call the file package that settles after training a model. To sum up, the model is the program file obtained after training and learning.
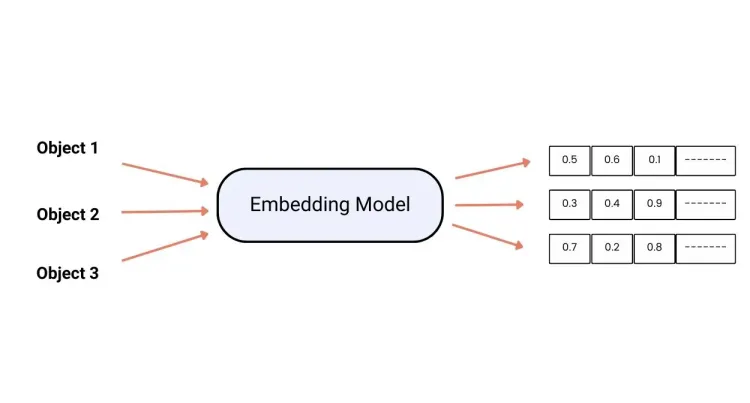
It is completely different from the data database we used before. What is stored in the model is not the original visible pictures, but the codes that analyze the image features.
Therefore, the model is more like a super brain that stores picture information. It will make predictions based on the prompt content we provide, automatically extract the corresponding fragment information, reorganize it, and finally output it into a picture.
Of course, the actual operating principle of the model is much more complicated than this. Still, as users, we do not need to study complex technical algorithms in-depth and just understand the general concept.
Re-understand the official model
In the previous article, a brief introduction to the composition and operating principles of the Stable Diffusion model was given. Before formally introducing the model type today, it is necessary to take you to re-understand this significant official model.
Have you ever wondered: With so many rich drawing models on the market today, why are the official Stable Diffusion models still talked about?
Of course, in addition to its powerful capabilities, more importantly, the cost of training such a complete architecture model from scratch is very high. According to official statistics, the training of the Stable Diffusion v1-5 version model used:
- 256 40G A100 GPUs (graphics cards dedicated to deep learning, benchmarking more than 3090 computing power)
- Taking a total of 150,000 GPU hours (about 17 years)
- The total cost reached $600,000.
- In addition, to verify the drawing effect of the model, with tens of thousands of testers producing 1.7 million pictures every day.
It is impossible to achieve today's Stable Diffusion without massive resource investment. Such a model can be freely open-sourced, which has greatly promoted the development of AI painting technology.
It stands to reason that the drawing effect of a model trained at such a high cost should be very powerful, right? But friends who have experienced it all know that compared with the drawing models blooming in the open-source community, the drawing effect of the official model is definitely not outstanding, and can even be said to be a bit disappointing. Why is this?

Here we use ChatGPT to compare then it is easy to understand. The underlying large model of ChatGPT is the GPT model, including GPT3.5, which was at its peak when it debuted, and GPT4, which later became popular on the entire network.
Although these models contain a large amount of basic knowledge, they cannot be used directly and require manual fine-tuning and guidance. Only when it is applied in real life, ChatGPT is an application in the chat field.
In the same way, Stable Diffusion is a large model focusing on the field of image generation. Its purpose is not to draw directly, but to do pre-training by learning massive image data to improve the overall basic knowledge level of the model so that it can use the powerful versatility and practicality of the application to complete subsequent downstream tasks.
In more popular terms, the official large model is like an all-inclusive encyclopedia. Although it collects the basic information required for AI drawing, it cannot meet the drawing needs for details and specific content, so I want to be directly promoted to a professional from this. The drawing tools are still a bit difficult.
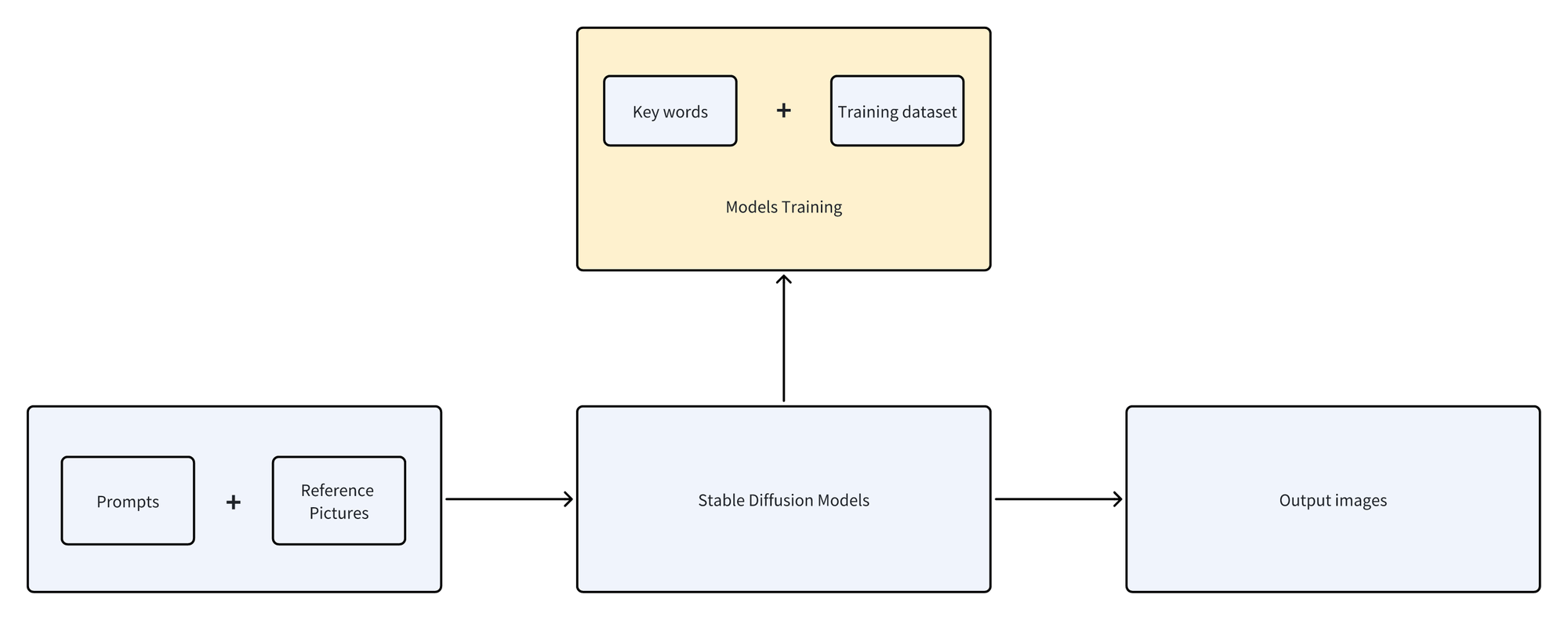
The real value of Stable Diffusion's official model is that it lowers the threshold for model training because the cost of training a new model based on an existing large model is much lower. Many alchemy enthusiasts, only need to add a small amount of text and image data to the official model and use the fine-tuning model training method to get a customized model for specific fields. On the one hand, the training cost is greatly reduced. You only need to train locally with a civilian-grade graphics card for a few hours to obtain a customized model with stable graphics. On the other hand, the understanding and drawing capabilities of the model trained in a specific direction are stronger, and the actual rendering effect has been greatly improved.
Common models
Now that we understand the value of official models, let’s formally introduce several models we usually use. Based on the differences in model training methods and difficulty, we can simply divide these models into 2 categories: one is the main model, and the other is the extended model used to fine-tune the main model.
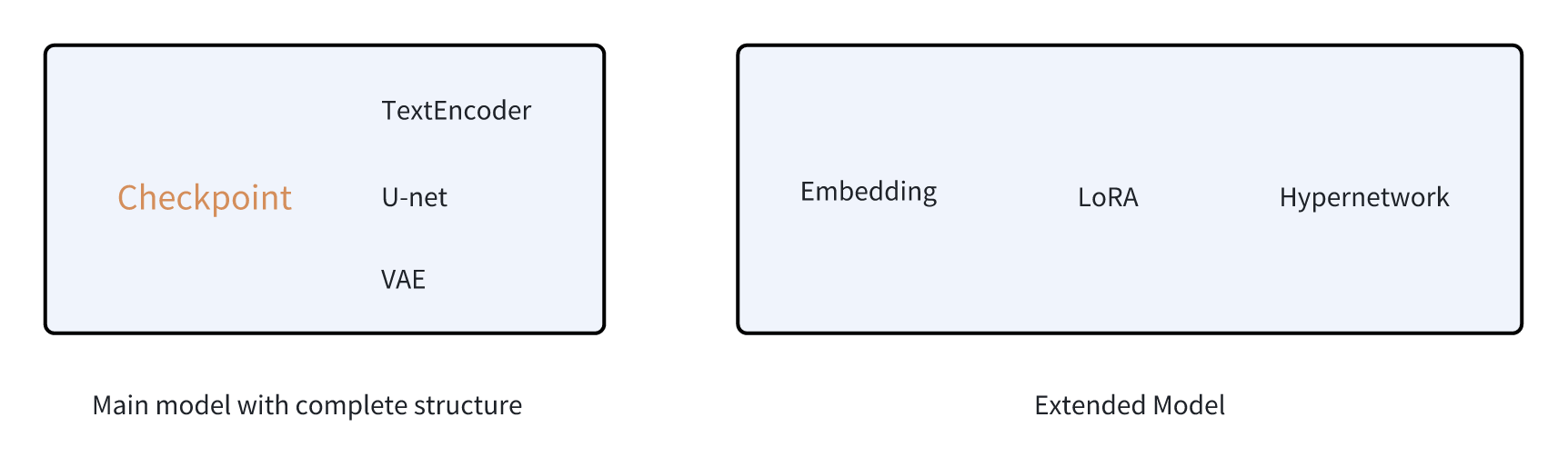
The main model refers to the standard model Checkpoint that includes TextEncoder (text encoder), U-net (neural network), and VAE (image encoder). It is obtained through comprehensive fine-tuning based on the official model. However, such a comprehensive fine-tuning training method is still difficult for ordinary users. It is not only time-consuming and labor-intensive but also has high hardware requirements. Therefore, everyone has gradually turned their attention to training some extended models, such as Embedding, LoRA, and Hypernetwork, through which With a suitable master model, good image control effects can also be achieved.
We can understand the main model as a textbook for a specific subject, while the extended model is a tutorial material or exercise book that supplements the content of the textbook.
I have sorted out the differences in functions and features of common models in the table below, and I will introduce them to you one by one in the following articles.