Stable Diffusion Models Study Guide: Embeddings
After introducing the main model, let's look at various extension models. The first is the lightest Embeddings model.
Although the Ckpt model contains a large amount of data information, but file packages of several GB are not portable enough to use. For example, sometimes we want to train a model that can reflect characteristics for use. It would be too laborious to fine-tune the parameters of the entire neural network every time. At this time, Embeddings needs to make its debut.
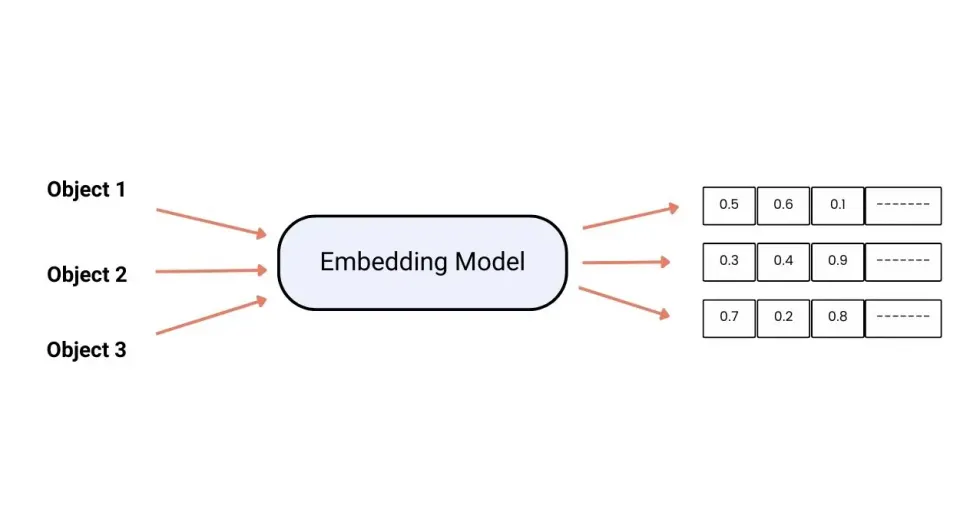
Embeddings are also called embedded vectors. In the previous introduction article, I introduced to you that the Stable Diffusion model consists of three parts: TextEncoder, Diffusion Model, and Image Encoder. The function of the TextEncoder is to convert the prompts into words that are converted into text vectors that can be recognized by computers, and the principle of the embedding model is to map information containing specific style features into it through training. When the corresponding keywords are entered later, the model will automatically enable this part of the text vector for drawing.
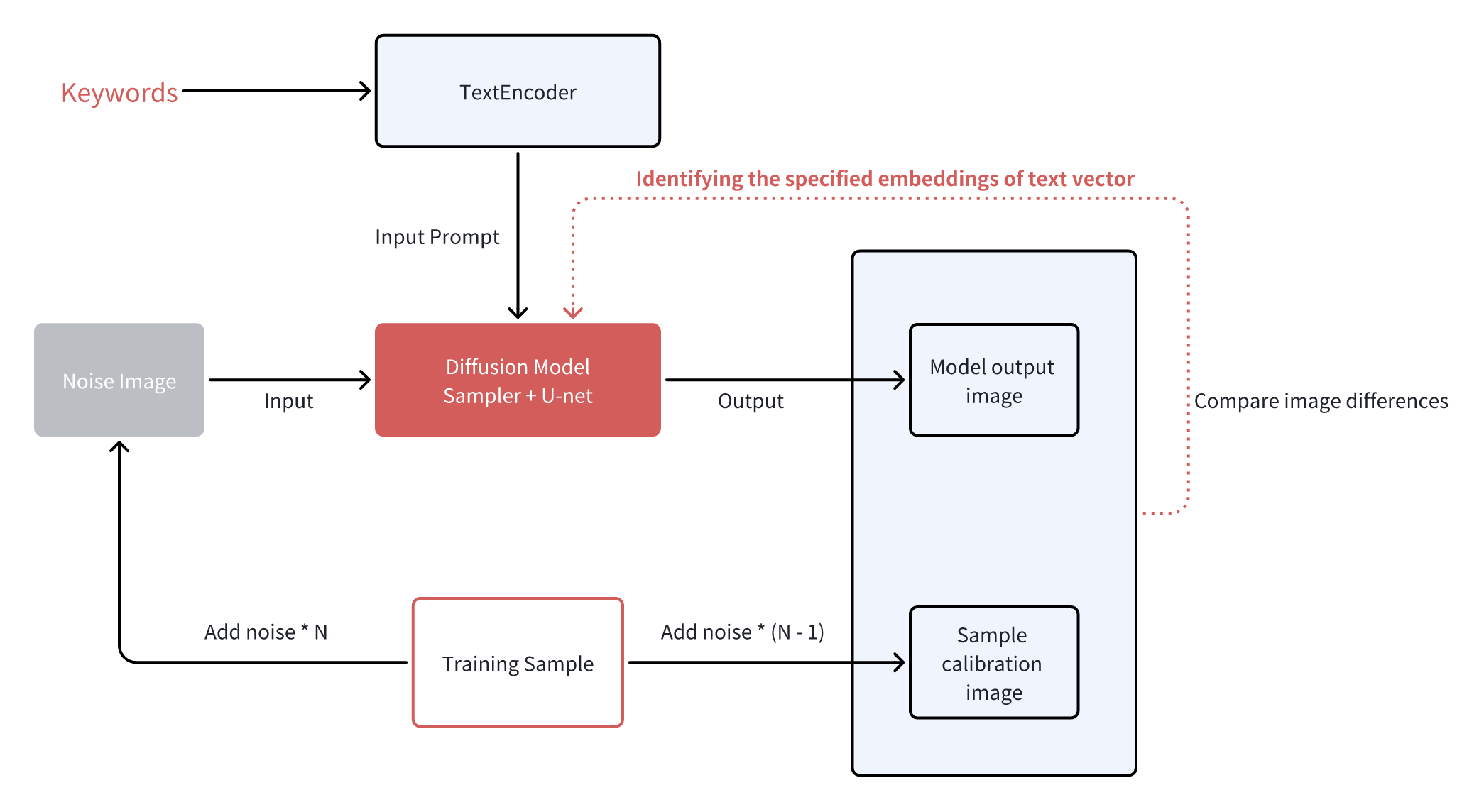
The process of training the embeddings model is based on the prompt text part, so the training method is called textual inversion. When embeddings and textual inversion are mentioned in the community, they both refer to the same model.
If you have downloaded embeddings model packages before, you will be surprised to find that they are generally very, very small, and some may only be tens of KB in size.
Why is there such a big volume gap between models? By analogy, Ckpt is like a thick dictionary, which contains characteristic information of many elements in the picture, while embeddings are like sticky notes. It does not store a lot of information itself but adds the required elements. Information is extracted and annotated. On this basis, we can also simply understand the embeddings model as an encapsulated prompt word file. By integrating the description information of a specific target into embeddings, we only need a short piece of code to call it later, and the effect is better than manual input. Much more convenient and fast. Our usual headaches of avoiding incorrectly drawn hands, facial deformations, and other information can be solved by calling Embeddings models, such as the most famous EasyNegative model.
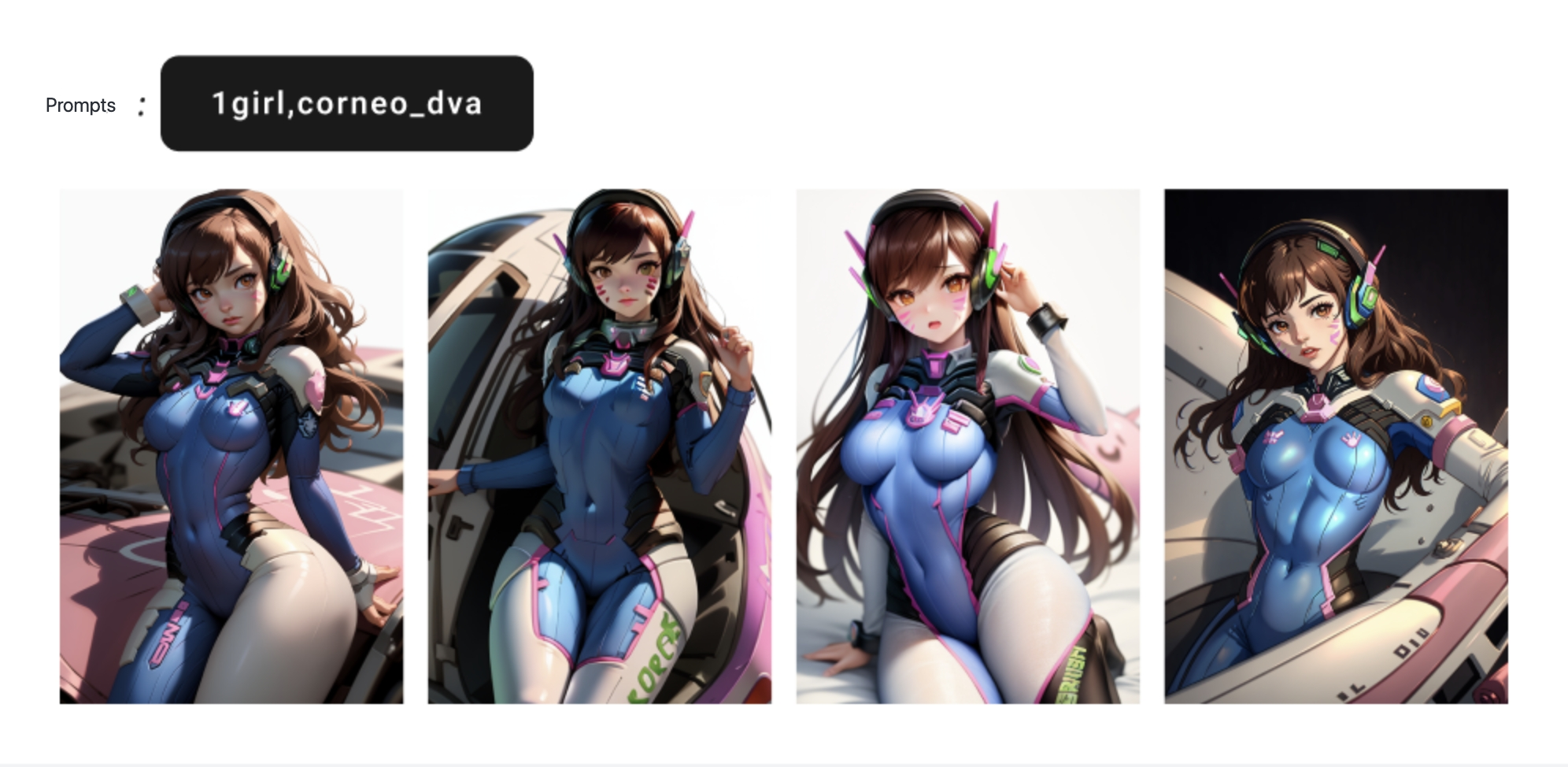
Take the popular character D.VA in Overwatch as an example. We all have a unified appearance consensus for this character, such as blue tights, brown hair, patterns on the face, etc. It is often difficult to express this information accurately if described through prompt words, but with embedding it is much easier. It can be seen that after calling D.VA's Embedding model, even the main models with different painting styles can achieve a relatively accurate restoration of the character image.
Of course, Embedding also has its limitations. Since the weight parameters of the main model are not changed, it is difficult to teach the main model to draw unseen image content, and it is also difficult to change the overall style of the image. Therefore, it is usually used to fix the characteristics of characters or screen content. The method of use is also very simple. Just place the downloaded model into the \embeddings folder under the Stable Diffusion installation directory. When using it, click on the corresponding model card, and the corresponding keywords will be added to the prompt word input box. When you click the Generate button, the model's drawing control effect will be automatically enabled.


