Stable Diffusion Models Study Guide: LoRA

Though embeddings models are lightweighted, they can only perform correction on top of the capabilities of the existing base model in the vast majority of cases. Isn't there a model that can stay lightweight yet store some information about images?
Here comes the LoRA model, which is famous for its performance. This model can provide a balanced solution between lightness and image retention, while also being well-suited for large datasets and fast processing.
LoRA is the acronym for "Low-Rank Adaptation Models." It refers to a technique developed by Microsoft researchers to address language model adjustments for large language models like GPT3.5 which has 1750 billion parameters.
Instead of conducting a full retraining each time, LoRA uses "low-rank insertion" to reduce the model parameter size and avoid the need to recalibrate the entire model's parameters.
It is a convenient method to augment existing models without any significant changes, greatly improving efficiency and model flexibility.
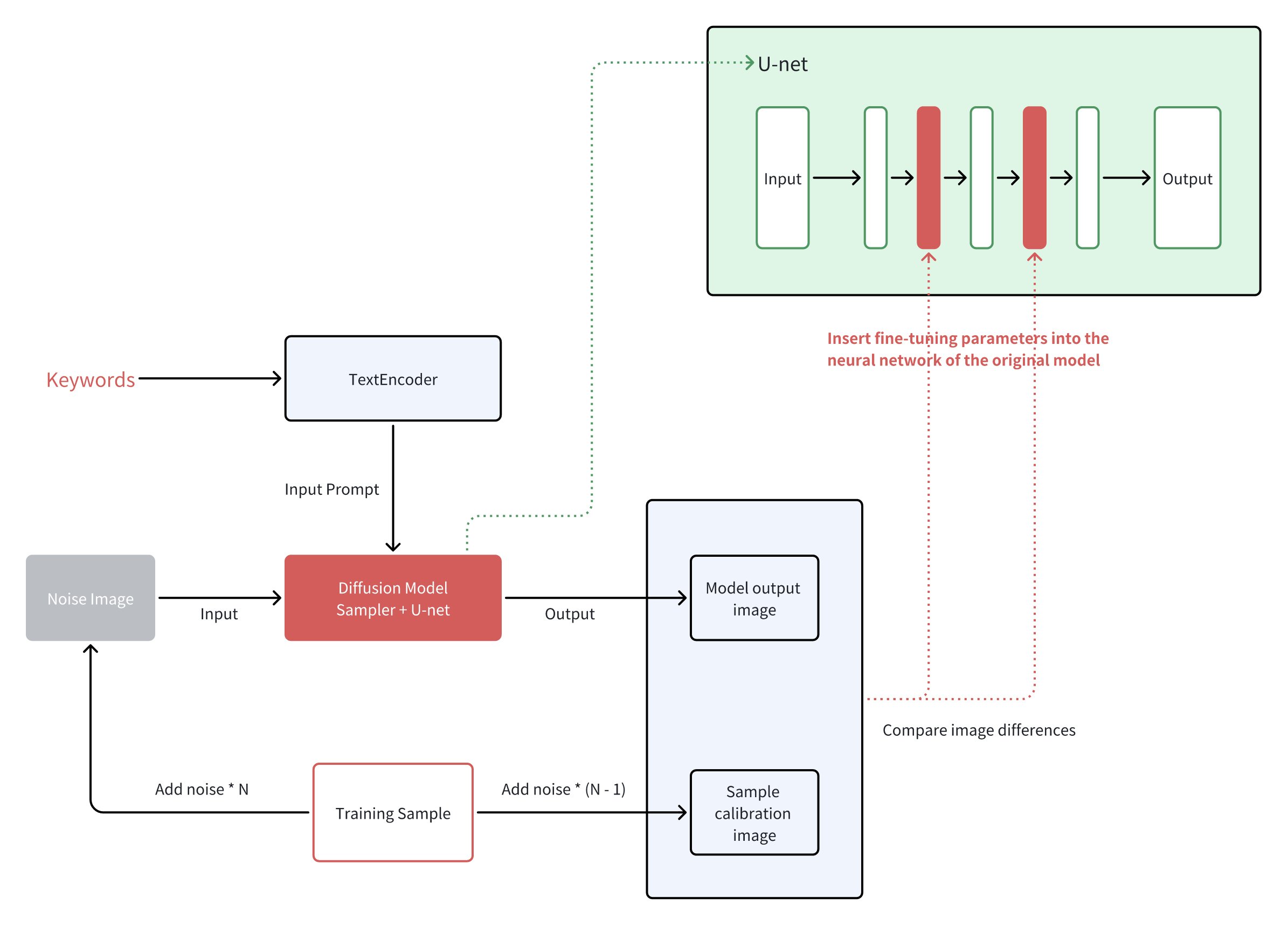
Compared to the "retraining the entire model" method used by Dreambooth, LoRA's training parameters can be reduced by thousands of times. This significantly lowers the hardware performance requirements and can dramatically reduce the training process for image processing. If embeddings are like sticky notes, LoRA would be the extra scrapbook pages that record more in-depth image features and details.
Since the number of parameters to be adjusted has been drastically reduced, the file size for a LoRA model is usually only a few hundred MBs in size, much smaller than an embedding model, yet much more enriching.
With its many advantages, including small model size, low training difficulty, and good image control performance, LoRA is quickly gaining traction amongst creators. The open-source community is flooded with plugins specifically engineered to enhance LoRA models, cementing its popularity as one of the most sought-after models currently available.
So, what are the specific applications of a LoRA model? In essence, it can be boiled down to "static and specific feature imagery," where the target can be either a person or an object. The fixed characteristics, which can range from gesture, age, expression, and clothing, to material, perspective, composition, and style, can be reproduced. So LoRA model has wide applications in fields like character reproduction, image aesthetics, scene design, and more, making it a popular choice for various creative applications.
The process of installing a LoRA model is similar to that of prior models. Simply extract the model and save it in the "models/Lora" folder.
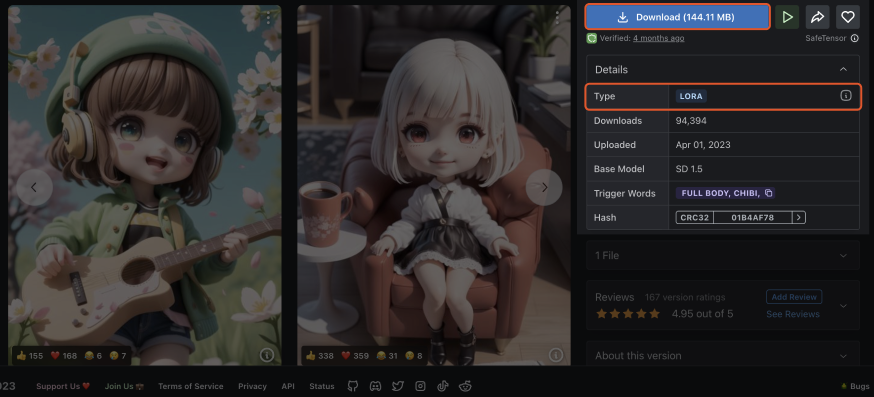
It is worth noting that some LoRA model authors may add some trigger words during training to enhance image recognition. You can see these trigger words indicated on the right side when you download the model.
It is highly recommended that these trigger words be present when using the LoRA models to improve their effectiveness. However, the trigger words should not just be added on a whim, as each word might represent a certain level of stylistic intricacy. If the model information page does not provide a list of trigger words, you may use the model as is.

