What is Stable Diffusion 3?

In the dead of night, Stability AI has released Stable Diffusion 3.0, employing the same DiT architecture as Sora, resulting in significantly improved visual quality, text rendering, and complex object comprehension. Compared to Midjourney and DALL-E 3, the release sets a new standard, making its predecessors pale in comparison.
Table of Contents
What is Stable Diffusion 3?
Compared to its predecessors, Stable Diffusion 3 generates images of significantly improved quality and supports multiple prompting themes, while text generation quality has been enhanced as well. Here are some showcase examples from the official release:

According to Stability AI, Stable Diffusion 3 is a series of models with varying parameter ranges from 800M to 8B. The parameter count implies the model can run directly on many portable devices with ease, significantly lowering the threshold for deploying large AI models.
Additionally, the company revealed SD 3 using diffusion transformer architecture, which is the same as Sora, and linked the peer-reviewed paper by William (Bill) Peebles about DiT. With 201 citations, the article has the potential to see a sharp increase in the year ahead.
However, Stable Diffusion 3 hasn't been released in full currently, with weight parameters unreleased as well. The team notes they are taking measures to prevent misuse by ill-intent parties. Users wanting to sample the model may click the link to apply.
According to CEO Emad Mostaque's X platform thread, he shares the model will be open-sourced after receiving feedback and undergoing improvements.
Techniques behind SD 3
In the blog entry, Stability AI announces the two key technologies that drove the construction of Stable Diffusion 3: Diffusion Transformer and Flow Matching.
Diffusion Transformer
Stable Diffusion 3 utilizes a Diffusion Transformer framework similar to OpenAI's Sora. Previous generations of Stable Diffusion models primarily relied on diffusion architecture.
The foundation of the transformer framework was initially developed by one of Sora's lead researchers, Bill Peebles, and assistant professor Xinyu Qin of New York University first released in Late 2022 and updated with a revision in March of 2023. The paper explores the significance of architecture choice in diffusion models and finds that it is not critical to performance, with the U-Net component easily replaced by standard design.

Specifically, the paper proposes a novel diffusion model with a Transformers structure, DiT. To achieve this, the research team trains a potential diffusion model, substituting a traditional U-Net root network with a Transformer to execute operations on potential patches. The researchers analyzed the scalability of the Diffusion Transformer (DiT) through the complexity of forward pass in Gflops, with each DiT model achieving satisfactory results.
The different approaches to expanding these models to support the generation of high-resolution images also vary. Existing methods either increase the complexity of the training process, require additional models, or sacrifice quality. Generative diffusion is the primary method to achieve high-resolution image synthesis, but in practice, it cannot accurately represent fine details, impacting the rendering quality. Other high-resolution image synthesis techniques, such as progressive super-resolution, multi-scale loss, additional multi-resolution inputs, and outputs, or utilizing adaptive and novel architecture designs have also been employed.
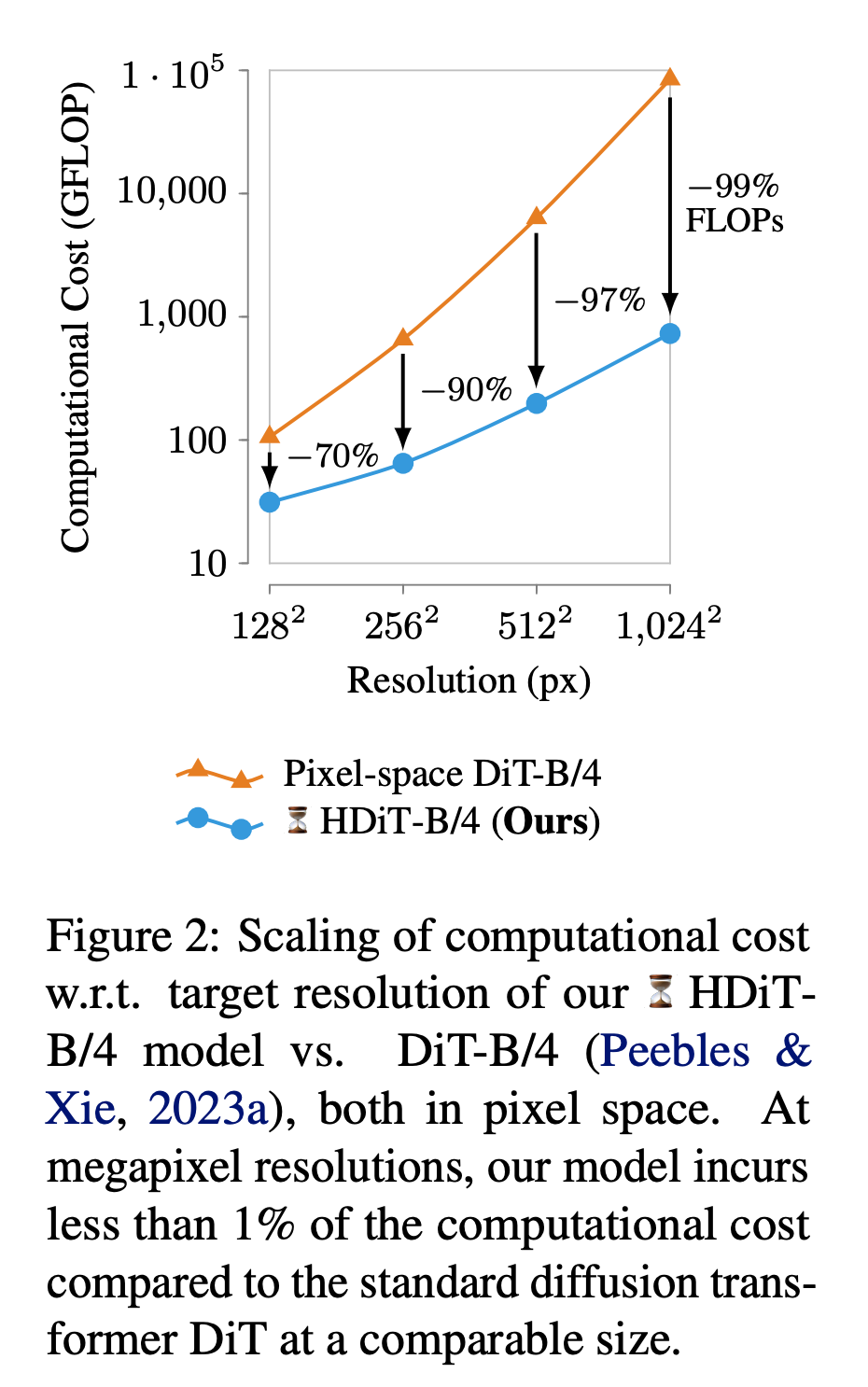
Inspired by DiT, Stability AI further proposes Hourglass Diffusion Transformer (HDiT). The model is an image generation model that scales along the pixel count, supporting direct training in high-resolution (such as 1024 × 1024 ) pixel space.
This work through the improvement of the backbone network effectively tackled the issue of high-resolution synthesis. The Transformers architecture can extend to tens of billions of parameters, while HDiT, building upon this foundation, remedies the gap between convolution U-Net efficiency and Transformers' scalability without resorting to the usual high-resolution training techniques, enabling successful training.

The researchers introduced a "pure transformer" architecture, achieving a backbone structure capable of generating million-pixel-grade images in standard diffusion settings. Despite the low spatial resolution, such as 128 × 128, the architecture demonstrates superior efficiency to commonly used Diffusion Transformers backbones like DiT (Figure 2), while also boasting competitive quality in output generation.
On the other hand, compared to convolution U-Net, HDiT also maintains competitiveness in computational complexity in high-pixel-resolution image synthesis in the pixel space.
Flow Matching
The significance of utilizing Flow Matching technique lies in improved sampling efficiency.
Deep generative models are capable of estimating and sampling from unknown data distributions. However, the constraints of simple diffusion processes limit the space of sampling pathways significantly, hence resulting in longer training times and the need for specialized methods to enhance sampling efficiency.
This research presents a novel paradigm on continuous normalized flow-based generative modeling, achieving a scale of training never seen before with CNF.

In concrete terms, the paper proposes the concept of "Flow Matching" as a method to train a CNF without simulation using the regression of a fixed condition probability vector field. Flow Matching is compatible with the class of universal Gaussian probability paths based on generalizability that incorporates the existing diffusion paths into specific instances.
Researchers discovered that employing Flow Matching accompanied by diffusion paths can provide a better, more stable alternative for training diffusion models.
Additionally, Flow Matching not only provides a pathway for using non-diffusion probability paths to train CNF, but it also opens up possibilities with optimal transport (OT) displacement interpolations used to define conditional probability pathways. These paths are more efficient than diffusion paths, training and sampling are faster, while generalization performance is enhanced. Training a CNF upon ImageNet with Flow Matching consistently yields superior performance in likelihood and sampling quality compared to other diffusion-based methods, and can leverage existing numerical ODE solvers for speedy and reliable sampling.



